
Why Was the Israeli Vaccine Study Really Deleted?
And why is a former Human Genome Project team leader trying to downplay these uncomfortable facts?

A deleted Israeli study claimed to detect Pfizer vaccine mRNA in blood, placenta, and semen. More interesting: they detected it in 50% of unvaccinated women, too. I reported here!
Kevin McKernan - former R&D team leader for the Human Genome Project - attempted to dismiss concerns about the study’s primers cross-reacting with human DNA.
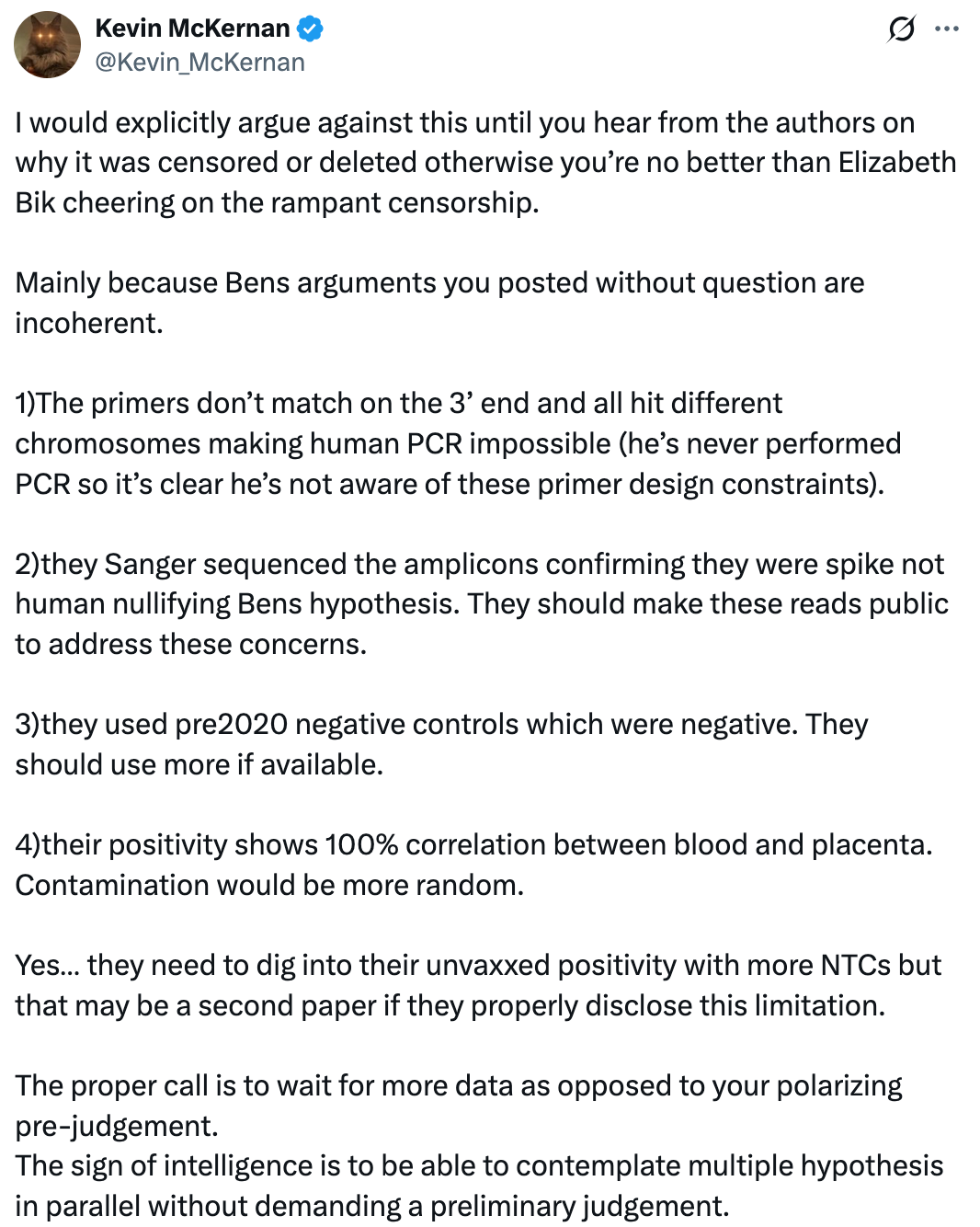
Curious response from a former Human Genome Project team leader - sloppy formatting (no spaces, inconsistent capitalization) paired with ad hominem attacks (”incoherent,” “never performed PCR,” “polarizing,” implying lack of intelligence) rather than addressing the actual science.
Besides this, his four arguments don’t hold up:
Point 1: “Primers don’t match on 3’ end”
Factually wrong. The nested forward primer (ACTTCACCGGCTGTGTGATT) shows a perfect 20/20 match to human Chromosome 1 (NC_000001.11) with q_start=1, q_end=20. The entire primer, including the 3’ end, aligns perfectly. E-value: 0.008.
Point 2: “Different chromosomes = impossible to amplify human DNA”
This assumes the SARS-CoV-2 genome is distinct from human sequences. But is it?
Edward Holmes - co-author of the original genome publication - confirmed that MN908947.1 contained human DNA:

The genome was assembled via MEGAHIT from mixed metagenomic reads - never from isolated viral material. Both the CDC (https://x.com/USMortality/status/1840501046910550277) and RKI (https://x.com/USMortality/status/1876650231850267129) have confirmed no viral genetic material was ever sequenced in isolation.
If “spike” sequences were derived from human reads misassembled as “viral,” then detecting them in unvaccinated humans isn’t cross-reactivity - it’s detecting endogenous human sequences that were mislabeled as viral from the start.
Point 3: “Sanger sequencing confirmed spike”
Circular logic. If spike was originally derived from human reads during genome assembly, confirming you found “spike” proves nothing about its origin. Also, where’s the raw data for public scrutiny?
Point 4: “Pre-2020 controls were negative”
Where’s the data? How many samples? What tissue types? Same PCR protocol?
Even if true - the sequence “appearing” in late 2019 coincides with when they created the reference genome from metagenomic assembly. That’s not proof of viral emergence.
The Real Question: Why Deleted?
The study wasn’t retracted - it was deleted. No DOI, no retraction notice, no explanation.
A retraction requires a formal process with a public record. Deletion leaves no trace.
If the problem were simply “bad primer design,” a retraction notice would suffice. But what if the study accidentally demonstrated something far more inconvenient?
50% of unvaccinated women tested positive for “spike” sequences. What if they weren’t detecting vaccine contamination or primer cross-reactivity - but rather human sequences that were incorrectly labeled as “viral” when the SARS-CoV-2 genome was first assembled in 2020?
Perhaps the study was deleted not because it was wrong, but because it was accidentally right about something it wasn’t supposed to find.
Background: Is the SARS-CoV-2 Genome Valid?
For those unfamiliar with my ongoing analysis:
1. The original SARS-CoV-2 genome (MN908947) was assembled from short metagenomic reads using MEGAHIT - a de Bruijn graph assembler that may create artificial contigs from k-mers. (more)
2. Early versions contained confirmed human DNA contamination.
3. No single long read (or at least several well overlapping long reads) spans the full 29,903 bp genome, that include the exact start and end.
4. All subsequent validation uses PCR primers derived from this unverified sequence (circular logic).
5. CDC and RKI confirm no viral material was ever sequenced in isolation.
👉 The deleted Israeli study may have inadvertently provided another data point supporting this hypothesis!
The human genome project was a bonanza for pcr/gene sequencing machines, and R01 grants from NIH. It helped create the myth that scientists know everything about humans including down to individual, never observed genetic nano particles. Billions and billions made.
Constant failures on it being unable to resolve any real health issues or diseases only led to the need for MORE large scale sequencing and computer modeling studies.
By this time in history its sure looking like just another money making “scientific” hoax
This doesn't make any sense Ben. Primers are designed in pairs for reasons: If the nested forward primer perfectly matches chromosome 1, then it can bind a specific site there. For the paired reverse primer to produce a DEFINED AMPLICON (as intended in nested PCR), it must bind to the complementary strand at an appropriate distance on the same contiguous sequence - which, in the human genome, means the same chromosome.
Primers binding to different chromosomes would not produce a consistent, amplifiable product in standard PCR conditions, as the template strands are not physically linked in that way during amplification. THM: No PCR product for PCR or nested PCR would occur from the primers you've listed/referenced.
So your hypothesis is wrong based on this claim, and if vaccine mRNA is indeed found in 50% of unvaccinated people then we need to find out why. But so far, it doesn't seem to be because the "vaccine-specific" primers were amplifying human DNA. I would think more toward "shedding" hypothesis.
As to speculating on why the paper disappeared, the authors will likely resubmit to a new journal. Stay tuned.